

What is Kafka?
The Cricket T20 world cup has just ended. Vikram was jubilant. India had won the Championship after 17 long years. Being a cricket freak, Vikram couldn’t stop talking about yesterday’s match among his friends. He became so engrossed that he forgot that he was in his Distributed Computing class and Professor Agaskar had already entered.
Agaskar sir, in his typical style, threw the chalk perfectly aimed at Vikram and asked,
“Vikram, you seem to have enjoyed the tournament very much. Can you tell me how we can design a Web Application that will provide real time score and match updates for multiple matches at the same time?”
Agaskar sir
Vikram stood, not out of fear, but out of respect for his professor and answered, “Sir, we can store the scores on a relational database like MySQL and show it to the end users”, Vikram replied.
“MySQL? Wrong!” claimed Agaskar sir. His words sounded like a quiz buzzer. The industry veteran turned professor answered. “In fact, we should never score real time scores onto a database directly. Unless you want your manager to throw the chalk over you like this”, he retorted, throwing another chalk at Vikram.
And that is when the entire class got introduced to an out-of-syllabus topic called Kafka.
Limitations of Databases and the Need for Kafka
To understand the need for Kafka, we first need to understand about the limitations of a Relational Database in the above-mentioned use case. Databases store the state of the data. As an example of the state information, let us say, you want to know the total score of a team in a match. We can store this data in an RDBMS and query it. So far so good.
But for streaming a cricket match live, we need to consider two things:
- Events
- Fast generation of event data
An event can be described as multiple values of data over a period. For example, in the 19th over of the 21st match, the ball-by-ball score was [6,6,4,4,2,0]. This data is getting generated very fast. Also, we need this data only for the real time. No one is going to see the ball-by-ball score after 10 years from when the cricket match got over.(Unless you are a cricket nerd like me!)
Another classical example of an event type of data can be found in a food delivery app. In a typical food delivery app, we can see the location of the delivery partner in real time. So somewhere, the latitudes and longitudes of the delivery partner is being recorded by a service for every second.
In both the cases, relational database will fail. Why?
Let us try to do a quick recap of what we learned in our primary school about computers. There are two types of memory, primary memory and secondary memory. Primary memory is fast but not durable. Secondary memory is durable but not fast.
A typical database uses Secondary memory because that is what databases are meant for: to store data permanently and retrieve them when needed. This durability comes at the cost of speed. So, if we run an “Insert” query every second for every latitude and longitude of a delivery partner in your database, the database will not be able to handle that and eventually lead to inconsistencies. So, what do we do now? We use a messaging system.
An application consists of a Producer service that generates event data. It also has a Consumer service that takes the data produced by the producer. The messaging System is nothing but a queue that sits in between the producer and the consumer.
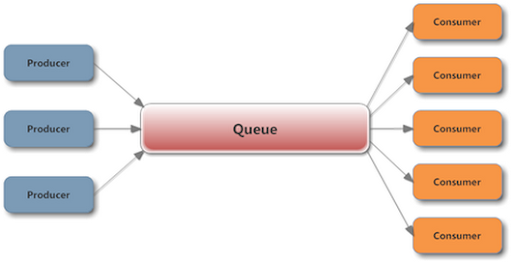
This queue is basically in the primary memory and is therefore very fast. However, we still have a problem. What if the data generated is so large that the queue gets filled very fast? Also, this design has a single point of failure, the queue itself. Is there a way to scale and distribute this queue? Well, there is a way and that way is Kafka! (drumrolls 🥁🥁)
Kafka and its Key terms
Apache Kafka is an open-source distributed streaming system designed for stream processing, real-time data pipelines, and data integration at scale. LinkedIn developed it to handle their real-time data feeds. In simple words, Kafka is a technology that enables distributing and scaling the queuing system used in real-time streaming applications. This technology is implemented as libraries in multiple programming languages including Java and JavaScript which we will investigate in our next blogs.
But first, let us try to understand the key terminologies used in Kafka
Producer
This is the service that generates real time event data. For example, in our cricket app, we can have a “Score tracking” component that acts as a producer.
Consumer
This is the service that uses the real time event data generated by the producer. For example, the web application frontend of the cricket app is our consumer.
Partition
Every queue that is used to store the data is called partition in Kafka’s terminology. The number of partitions is called as partition count
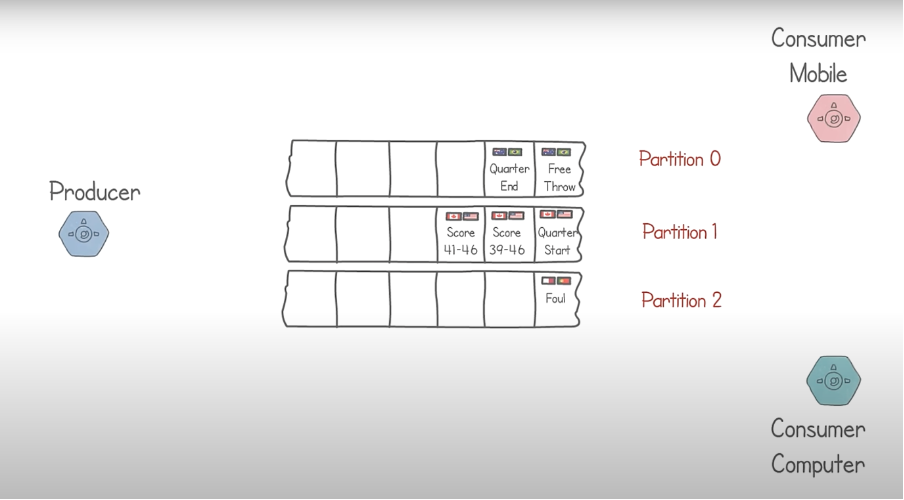
Broker
The physical server that holds one or more partitions is called as a Broker.
Record
The unit of data that is stored in the partition is called a “Record”.
Partition key
It is the key used to identify to which partition a particular record needs to be stored. This is provided by the application itself usually. If the application does not provide any partition key, Kafka assigns a random key value. This is needed to ensure that the consumer gets correct data.
If partition key does not exist, the data would have to be stored in random partitions and we can’t get the accurate data in real time. For example, if there are two cricket matches going on at the same time, it makes sense, to store all records of an individual match in a single partition so that consumer process can easily fetch the data and aggregate it for the end user. In this case, the “Match Name” or “Match Number”, anything that uniquely identifies a match, can be given as a partition key.

Topic
A topic groups partitions with similar types of data. For example, if we have men’s and women’s world cup tournaments happening simultaneously, we can group all partitions containing events of the men’s matches into a topic called “Men.” Similarly, we can group all partitions containing events of the women’s matches into a topic called “Women.”
Offset
An offset is a number assigned to each data stored in the partition. It is sequential. We can access a particular data point using the partition number and the offset, much like how we access an element in a 2D array.

Conclusion:
For real-time streaming applications generating event-type data, we cannot use relational databases. We need an intermediate queuing system. Kafka enables us to distribute and scale this intermediary queue. In a typical Kafka application, the producer component generates events, and the consumer process consumes the data generated by the producer. The individual queues are called partitions, and the server hosting one or more partitions is called a broker. The event data distributes among the partitions based on their partition keys. Partitions with similar types of data group into topics. Each data stored in the partition is a record, uniquely identified by its offset and partition number.
Reference:
https://www.youtube.com/watch?v=Ch5VhJzaoaI (Special thanks to James Cutajar)
https://aiven.io/blog/apache-kafka-and-the-great-database-debate
You will also like to read our Introduction to Docker blog here.




Your articles are extremely helpful to me. Please provide more information!